Definition: Polynucleotide
A polynucleotide is a long chain formed by the joining of many nucleotide monomers.
Transfection is the process of inserting a vector into eukaryotic cells.
Definition: Nucleoid
The nucleoid is the region in prokaryotic cells where DNA is organised and associated with proteins, despite the absence of a true nucleus.
Definition: NHC Proteins
Proteins other than histones that are associated with chromatin and help in higher-order DNA packaging and regulation are called non-histone chromosomal (NHC) proteins.
Definition: Nucleosome
The basic repeating unit of chromatin formed by DNA wrapped around a histone octamer is called a nucleosome.
Definition: Chromatin
The thread-like complex of DNA and proteins present in the nucleus of eukaryotic cells is called chromatin.
Definition: DNA packaging
The process by which a very long DNA molecule is compactly organised inside the cell nucleus so that it fits within the limited nuclear space and remains functional is called DNA packaging.
Definition: Histone Octamer
A structural unit composed of eight histone protein molecules around which DNA is wrapped is called a histone octamer.
Definition: Histones
Positively charged basic proteins rich in lysine and arginine that associate with DNA to help pack it in eukaryotic cells are called histones.
Definition: Replication
The process by which DNA duplicates itself is called replication.
Definition: Heterocatalytic Function
When DNA directs the synthesis of chemical molecules other than itself, such functions of DNA are called heterocatalytic functions. Eg, Synthesis of RNA (transcription), synthesis of protein (Translation), etc.
Definition: Autocatalytic Function
When DNA directs its own synthesis, this function is called the autocatalytic function. Eg., replication.
Definition: Conservative Replication
Conservative replication is a mode of DNA replication in which the original parental DNA molecule remains intact, and a completely new DNA molecule is synthesised.
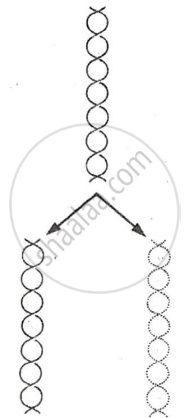
Conservative Replication
Definition: Dispersive Replication
Dispersive replication is a mode of DNA replication in which the parental DNA is broken into fragments, and each daughter DNA molecule contains a mixture of old and new DNA segments.
Dispersive replication
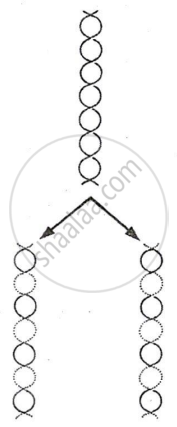
Definition: Semi-Conservative Replication
Semi-conservative replication is a mode of DNA replication in which each daughter DNA molecule consists of one parental (old) strand and one newly synthesised strand.
Semi-Conservative Replication
The movement of the ribosome from one end of the mRNA to the other end by the distance of one triplet codon during translation is known as translocation.
A sudden change that occurs in the nucleotide sequence of a gene, causing either a minor or considerable change in the characters of an individual is known as mutation.
Definition: Central Dogma
The central dogma is the principle that genetic information flows in one direction in a cell, from DNA to RNA to protein.
or
Central Dogma is the process by which genetic information flows from DNA to RNA to protein, controlling cellular functions and body structure.
A sequence of three adjacent nucleotides in mRNA that codes for one amino acid is known as a codon.
Translation is the process by which tRNA having anticodon to the codon on the mRNA, supplies amino acids, as per the message on mRNA.
Definition: Reverse Transcription
Reverse transcription is the process by which DNA is synthesised from an RNA template.
\[\mathrm{RNA}\quad\xrightarrow{\text{reverse transcription}}\quad\mathrm{DNA}\quad\xrightarrow{\text{transcription}}\quad\mathrm{mRNA}\quad\xrightarrow{\text{translation}}\quad\mathrm{Protein}\]
Definition: Transcription
The process of synthesising mRNA from the complementary nucleotide sequence of one DNA strand, in which uracil replaces thymine, is called transcription.
or
The process of copying genetic information from one strand of the DNA into RNA is termed as transcription.
Definition: Genetic Code
The genetic code is the specific sequence of nitrogenous bases in DNA that determines the order of amino acids in a protein.
Definition: Triplet Codon
A sequence of three nucleotides on mRNA that codes for a specific amino acid is called a triplet codon.
Definition: Translation
The process of protein synthesis in which the message on mRNA is decoded using tRNA to form a specific sequence of amino acids is called translation.
Definition: DNA Fingerprinting
The technique of identifying an individual by analysing the unique DNA sequence present in each person, similar to fingerprints, is called DNA fingerprinting.
Key Points: Deoxyribonucleic Acid (DNA)
- DNA was established as the primary genetic material and formally modelled as a double helix by Watson and Crick in 1953.
- The structural blueprint relied heavily on Erwin Chargaff’s chemical base equivalence rules and Rosalind Franklin’s X-ray diffraction data.
- The fundamental building block of DNA is a nucleotide, which comprises a five-carbon deoxyribose sugar, a phosphate group, and a nitrogenous base.
- A nucleotide is distinct from a nucleoside, as a nucleoside contains only the nitrogenous base and pentose sugar without the attached phosphate group.
- The double helix is formed by two antiparallel polynucleotide chains running in opposite directions (5′→3′ and 3′→5′) coiled in a clockwise, right-handed fashion.
- The physical architecture places the hydrophilic sugar-phosphate backbone on the exterior, while the information-carrying nitrogenous bases stack flat on the interior.
- Structural stability is maintained horizontally by complementary base pairing (A = T via two hydrogen bonds; G = C via three hydrogen bonds) and vertically by strong covalent phosphodiester bonds.
Key Points: Structure of Polynucleotide Chain
- A nucleotide has three parts: a nitrogenous base, a pentose sugar and a phosphate group.
- Sugars differ → RNA has ribose; DNA has deoxyribose.
- Two types of bases:
- Purines → Adenine (A), Guanine (G)
- Pyrimidines → Cytosine (C), Thymine (T), Uracil (U)
- Cytosine is common to both DNA and RNA; thymine is in DNA, and uracil is in RNA.
- Nucleoside = base + sugar; nucleotide = nucleoside + phosphate group.
- Nucleotides join by 3′–5′ phosphodiester bonds to form a polynucleotide chain.
- The chain has a 5′ end (free phosphate), a 3′ end (free OH), and a backbone made of sugar and phosphate.
Key Points: Packaging of DNA Helix
Prokaryote vs Eukaryote Packaging
| Feature |
Prokaryotes |
Eukaryotes |
| Nucleus |
Absent (nucleoid region) |
Present (true nucleus) |
| DNA nature |
Circular, naked (no histones) |
Linear, associated with histones |
| Packaging proteins |
HU proteins, DNA gyrase, Topo I, RNA connectors |
Histones (H1, H2A, H2B, H3, H4) + NHC proteins |
| Packaging mechanism |
Supercoiling + looping |
Nucleosome → Solenoid → Loops → Chromosome |
| Basic repeating unit |
Loop domain |
Nucleosome |
| Levels of compaction |
2 main levels (loops + supercoils) |
5–6 hierarchical levels |
| Charge of packaging proteins |
Positively charged (HU) |
Positively charged (histones) |
Key Points: Search for Genetic Material
- The discovery of nuclein and the proposal of the principles of inheritance occurred simultaneously, yet confirming DNA as the genetic material required considerable time.
- By 1926, the scientific investigation into the mechanisms of genetic inheritance had advanced to the molecular level.
- Cumulative research by scientists such as Mendel, Sutton, and Morgan successfully narrowed the source of genetic inheritance to chromosomes within the cellular nucleus.
- Key historical milestones include Hofmeister's 1848 observation of chromosomes during mitosis and Miescher's 1869 isolation of nuclein, which Altman later renamed nucleic acid.
- By 1920, the establishment that chromosomes are composed of both proteins and DNA initiated further experimental studies to identify the exact molecular carrier of genetic information.
Key Points: Griffith’s Experiment
- Frederick Griffith's 1928 experiments on Streptococcus pneumoniae shifted from developing a pneumonia vaccine to investigating the transmission of bacterial virulence.
- The study compared two distinct bacterial variants: the virulent, encapsulated S (Smooth) strain and the harmless, non-encapsulated R (Rough) strain.
- Baseline experimental controls established that mice survived injections of either the live R strain or the heat-killed S strain independently, but perished when injected with the live S strain.
- The pivotal final experiment revealed that injecting a mixture of live R strain and heat-killed S strain unexpectedly caused fatal pneumonia, resulting in the recovery of live S strain bacteria.
- Griffith concluded that a heritable "Transforming Principle" transferred from the dead S strain and assimilated by the live R strain, converting it into a virulent phenotype.
- While the experiment successfully demonstrated genetic transformation, it was limited by its inability to biochemically identify the transforming substance or confirm it as DNA.
Key Points: Avery, McCarty and MacLeod’s Experiment
- In 1944, Oswald T. Avery, Colin M. MacLeod, and Maclyn McCarty proved that DNA is the genetic material (transforming principle).
- They used cell-free extracts from heat-killed S-strain bacteria and mixed them with harmless R-strain bacteria.
- Only DNA could transform the R strain into the virulent S strain, demonstrating its role in heredity.
- Treatment with proteases and RNases did not stop transformation, proving that protein and RNA are not genetic material.
- Treatment with DNase stopped transformation, confirming that DNA is responsible.
- This experiment provided strong evidence that DNA is the hereditary material, though final confirmation came later from the Hershey-Chase experiment.
Key Points: The Hershey-Chase Experiment
- In 1952, Alfred Hershey and Martha Chase proved that DNA is the genetic material using bacteriophages and E. coli bacteria.
- They used radioactive isotopes: ³²P to label DNA and ³⁵S to label proteins.
- Viruses grown in ³²P medium had radioactive DNA, while those grown in ³⁵S medium had radioactive protein.
- These labelled viruses were allowed to infect E. coli, and then blending and centrifugation were done to separate viral coats.
- Only bacteria infected with ³²P-labelled viruses became radioactive, showing that DNA entered the bacterial cells.
- Bacteria infected with ³⁵S-labelled viruses were not radioactive, proving proteins did not enter the cells; hence, DNA is the genetic material.
Key Points: Properties of Genetic Material
- DNA is the primary genetic material in most organisms, while RNA acts as genetic material in some viruses.
- A genetic material must be capable of replication, which both DNA and RNA can achieve through base pairing.
- DNA is chemically and structurally more stable than RNA because it lacks the reactive 2′-OH group and contains thymine instead of uracil.
- Both DNA and RNA can undergo mutations, but RNA mutates faster due to its unstable nature, leading to rapid evolution in RNA viruses.
- DNA stores genetic information efficiently, whereas RNA helps express and transmit it through protein synthesis.
Key Points: RNA World
- Discovery of Ribozymes - Sidney Altman and Thomas Cech independently discovered that RNA can act as a biocatalyst.
- RNA World hypothesis - The RNA World hypothesis suggests that early life was based exclusively on nucleic acids, most probably RNA, and was first proposed by Carl Woese, Francis Crick, and Leslie Orgel in 1960.
- Evidence for RNA World - RNA is found abundantly in all living cells, structurally related to DNA, and can evolve, replicate, and catalyse reactions.
- Formation of primitive cells - RNA molecules underwent replication, mutation, and developed their own machinery to form primitive cells.
- Formation of DNA - Double-stranded DNA formed eventually, resulting in rich biodiversity.
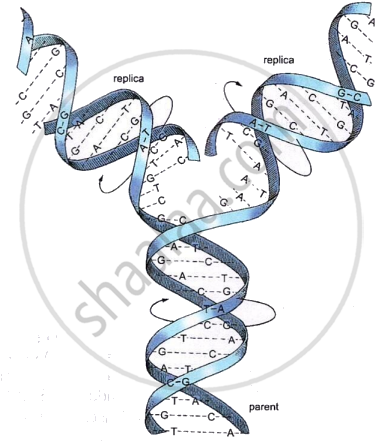
Key Points: DNA Replication
- DNA replication is the process by which a DNA molecule makes exact copies of itself, each parental strand acting as a template for a new complementary strand, giving two identical daughter molecules with one old and one new strand each (semi-conservative).
- It occurs during the S-phase (Synthesis phase) of interphase in the cell cycle.
- Proposed by Watson and Crick (1953) and experimentally confirmed as semi-conservative by Meselson and Stahl (1958) in E. coli.
- Of the three proposed models, the semi-conservative model was proved correct, while the conservative and dispersive models were disproved.
- Replication is an autocatalytic function (DNA making DNA), unlike heterocatalytic functions, in which DNA directs the synthesis of other molecules, such as RNA (transcription) or protein (translation).
Key Points: Meselson and Stahl’s Experiment
- The experiment was performed by Meselson and Stahl in 1958 using E. coli, which divides every 20 minutes and is easy to track across generations.
- Bacteria were grown in heavy nitrogen (¹⁵N) medium, then shifted to light nitrogen (¹⁴N) medium, and their DNA was separated by CsCl density gradient centrifugation.
- After the first replication, a single hybrid band appeared, which ruled out the conservative model.
- After the second replication, one hybrid and one light band appeared, which ruled out the dispersive model.
- These results proved that DNA replication is semi-conservative, where each new DNA molecule has one old strand and one new strand.
Key Points: Enzymes Used in DNA Replication
| Enzyme |
Function |
| Primase |
Synthesises short RNA primers (A, U, G, C), providing a free 3′-OH end |
| Helicase |
Unwinds the DNA double helix |
| Topoisomerase |
Relieves supercoiling; cuts and rejoins one strand ahead of the fork |
| DNA Polymerase |
Adds deoxyribonucleotides to the 3′-OH end; synthesises only in 5′ → 3′ direction |
| DNA Ligase |
Joins DNA fragments by forming phosphodiester bonds between 3′-OH and 5′-phosphate ends |
| Repair Enzymes (Nucleases) |
Correct replication errors as part of the polymerase complex |
Key Points: Mechanism of DNA Replication
- Replication starts at the origin (ori), where helicase unwinds the DNA helix to form a replication fork, topoisomerase relieves supercoiling, and SSBPs keep the strands apart.
- Primase lays down a short RNA primer, giving DNA polymerase a free 3′-OH end to start adding nucleotides.
- The leading strand is made continuously (one primer); the lagging strand is made discontinuously as Okazaki fragments (many primers).
- DNA Pol I removes the primers and fills the gaps, and DNA ligase seals the nicks into a continuous strand.
- Termination occurs when forks meet at the Ter site (prokaryotes) or when replicons fuse (eukaryotes).
Key Points: Protein Synthesis
- Protein synthesis is the process by which cells produce proteins, which act as structural components, enzymes, and hormones.
- It involves two main steps: transcription (DNA → RNA) and translation (RNA → protein).
- In transcription, genetic information from DNA is copied into mRNA, where uracil (U) replaces thymine (T).
- Central dogma, proposed by Francis Crick (1958), states that information flows from DNA → RNA → protein.
- In retroviruses, reverse transcription occurs (RNA → DNA), as explained by Temin and Baltimore (1970) using RNA-dependent DNA polymerase.
Key Points: Reverse Transcription (Teminism)
- Reverse transcription is the synthesis of complementary DNA (cDNA) from an RNA template by the enzyme reverse transcriptase (RNA-dependent DNA polymerase).
- It is also called Teminism, after Howard Temin, and occurs only in retroviruses.
- It contradicts the Central Dogma, since the flow here is RNA → DNA (not DNA → RNA).
- Discovered independently in 1970 by Temin and Baltimore in retroviruses.
- They won the 1975 Nobel Prize (with Dulbecco); it laid the foundation for retrovirology.
Key Points: Transcription
- Transcription is the process by which genetic information from one DNA strand (the template strand) is copied into RNA using RNA polymerase.
- It occurs in the nucleoid in prokaryotes and in the nucleus in eukaryotes; mRNA then moves to the cytoplasm for translation.
- A transcription unit has three parts: promoter (start site), structural gene, and terminator (stop site).
- The process occurs in three stages: initiation (RNA polymerase binds the promoter), elongation (the RNA chain is formed), and termination (RNA polymerase detaches).
- Only one DNA strand acts as a template (3′→5′), while the other is the coding strand (5′→3′).
- In eukaryotes, primary RNA (hnRNA) is processed by capping, tailing, and splicing to form mature mRNA.
Key Points: Transcription Unit
| Component |
Location |
Function |
| Promoter |
At the 5′ end of the structural gene |
Provides a binding site for RNA polymerase and initiates transcription |
| Structural Gene |
Between promoter and terminator |
Contains genetic information to be transcribed |
| Template Strand |
DNA strand with 3′ → 5′ polarity |
Serves as a template for RNA synthesis |
| Coding Strand |
DNA strand with 5′ → 3′ polarity |
Does not code directly; used as a reference strand |
| Terminator |
At the 3′ end of the coding strand |
Signals the end of transcription |
Key Points: Process of Transcription in Bacteria
- A single RNA polymerase synthesises all types of RNA (mRNA, tRNA, rRNA).
- Initiation starts when RNA polymerase binds to the promoter region.
- Elongation occurs via complementary base pairing of nucleotides.
- Termination happens at a terminator sequence, releasing RNA.
- No mRNA processing; transcription and translation occur simultaneously.
Key Points: Process of Transcription in Eukaryotes
- Transcription copies DNA → RNA using RNA polymerase, following complementarity rules (A pairs with U).
- In eukaryotes, 3 RNA polymerases: Pol I (rRNA), Pol II (hnRNA → mRNA), and Pol III (tRNA, 5S rRNA, snRNA).
- The template strand has 3′→5′ polarity; RNA is synthesised 5′→3′.
- Transcription unit = Promoter + Structural Gene + Terminator.
- In eukaryotes, the primary transcript = hnRNA, which contains both exons and introns.
- 3 processing steps: Splicing (remove introns) → 5′ Capping (m⁷G) → 3′ Poly-A tailing (200–300 A residues).
- Mature mRNA is transported to the cytoplasm for translation.
Key Points: Genetic Code
- The genetic code is the information encoded in the base sequence of DNA/mRNA that determines the amino acid sequence of a protein.
- It is a triplet code - three consecutive bases form one codon, proposed by George Gamow (1954).
- There are 64 codons in total: 61 code for amino acids and 3 are stop codons (UAA, UAG, UGA).
- AUG is the start codon and codes for methionine.
- It was deciphered primarily by Nirenberg, Khorana, and Ochoa (poly-U mRNA showed that UUU encodes phenylalanine).
- It is degenerate (one amino acid can have several codons, usually differing in the third base - the wobble effect) and nearly universal.
- A change in the base sequence alters the amino acid sequence, so the code directly controls protein synthesis.
Key Points: Characteristics of the Genetic Code
- The genetic code is a triplet code, that is, three consecutive bases form one codon and specify one amino acid.
- It has distinct polarity and is always read in the 5’ → 3’ direction.
- The genetic code is non-overlapping, so one base is a part of only one codon.
- It is commaless, which means there is no gap or punctuation between successive codons.
- The genetic code is degenerate, so one amino acid may be coded by more than one codon.
- It is universal or nearly universal because the same codon usually specifies the same amino acid in most organisms.
- It is non-ambiguous, so one codon codes for only one specific amino acid.
- AUG is the initiation codon and also codes for methionine.
- UAA, UAG and UGA are stop codons and do not code for any amino acid.
- Codon is written as 5’ AUG 3’, while anticodon is written as 3’ UAC 5’.
Key Points: Mutations and Genetic Code
- A mutation is a sudden change in the DNA sequence that alters the genotype and provides raw material for evolution.
- It may involve deletion (loss) or insertion/duplication (gain) of a DNA segment.
- A point mutation changes a single base pair - e.g., in sickle cell anaemia, glutamate is replaced by valine in the beta-globin gene.
- A frameshift mutation (insertion/deletion of one or two bases) shifts the reading frame, while adding/removing three bases changes whole codons but keeps the frame intact.
- Analogy "RAM HAS RED CAP": one or two extra letters disturb the triplet grouping, but three extra letters keep it unchanged.
Key Points: tRNA – the Adapter Molecule
- tRNA is the adapter molecule (Crick) that picks up amino acids and matches them to the correct mRNA codon.
- Robert Holley proposed the cloverleaf model (2D); in 3D, tRNA looks like an inverted L.
- It has three arms - DHU (binds aminoacyl-tRNA synthetase), anticodon (pairs with codon), TΨC (binds ribosome) - plus a 3′ CCA end for amino acid attachment.
- The amino acid is attached by aminoacyl-tRNA synthetase in a process called aminoacylation (charging), which needs energy.
- Each amino acid has a specific tRNA, with a special initiator tRNA for translation start; no tRNAs exist for stop codons.
Key Points: Translation
- Translation is the process by which the codon sequence on mRNA is decoded with the help of tRNA at the ribosome to form a specific sequence of amino acids in a protein.
- It needs mRNA (template), tRNA (adapter), ribosome (with A, P, and E sites), amino acids, aminoacyl-tRNA synthetase, ATP/GTP for energy, and Mg²⁺ ions.
- Before translation, amino acids are activated and linked to their specific tRNAs (charging) by aminoacyl-tRNA synthetase.
- Initiation: the small ribosomal subunit binds mRNA at the start codon (AUG), the initiator tRNA carrying methionine attaches, and the large subunit joins to form the initiation complex.
- Elongation: amino acids are added one by one through codon–anticodon pairing; peptide bonds form between them, and the ribosome moves forward by one codon at a time (translocation).
- Termination occurs at a stop codon (UAA, UAG, UGA), where release factors free the polypeptide and the ribosomal subunits separate.
Key Points: Regulation of Gene Expression
- Gene regulation = switching genes ON or OFF based on the cell's requirements and developmental stage.
- In eukaryotes, regulation occurs at 4 levels: Transcriptional (primary transcript), Processing (splicing), Transport (mRNA from nucleus to cytoplasm), and Translational.
- In prokaryotes, control of the transcriptional initiation rate is the primary mechanism of gene expression control.
- E. coli produces β-galactosidase to break lactose → galactose + glucose. If lactose is absent, the enzyme is not produced, proving the environment regulates gene expression.
- Enzymes synthesised in response to substrate availability are called inducible enzymes. The process is induction; the triggering molecule is the inducer. This is a positive control.
- Feedback repression = when the end product (e.g., amino acid) is already available, genes for its production are switched OFF. This is a negative control.
Key Points: The Lac Operon
- The lac operon is an inducible operon in E. coli, proposed by Jacob and Monod (1961), that controls lactose metabolism.
- It consists of a regulator gene (i), promoter (P), operator (O), and three structural genes - lac Z, lac Y, lac A - coding for β-galactosidase, permease, and transacetylase, respectively.
- When lactose is absent, the regulator gene produces an active repressor that binds the operator and blocks RNA polymerase, so the operon remains switched OFF.
- When lactose is present, lactose is converted into allolactose (the inducer), which binds the repressor and inactivates it, leaving the operator free.
- RNA polymerase then transcribes the structural genes into a single polycistronic mRNA, producing the enzymes that break down lactose – the operon is now switched ON.
Key Points: Human Genome Project
- The Human Genome Project (HGP) was an international mega-project launched in 1990 and completed in 2003, coordinated mainly by the U.S. DOE and NIH.
- Its aim was to identify all human genes and to sequence the entire human genome, about 3 billion base pairs.
- The main goals were to identify genes, sequence the genome, store the data, develop analysis tools, transfer technologies, and address ethical issues.
- Methodology: DNA was isolated, fragmented, cloned into vectors like BACs and YACs, sequenced by automated methods, and assembled using computers.
- Salient features: the genome has ~3 billion base pairs and 20,000–25,000 genes; less than 2% of the genome codes for proteins, and humans are 99.9% identical.
- Most genetic variation between individuals is due to single-nucleotide polymorphisms (SNPs).
- Applications: disease gene mapping, early diagnosis, personalised medicine, evolutionary studies, and advances in biotechnology.
- ELSI (Ethical, Legal, Social Issues): genome data must be kept confidential to prevent misuse and discrimination.
Key Points: DNA Fingerprinting
- DNA fingerprinting is a technique used to identify an individual by analysing the unique DNA pattern present in every person (except identical twins).
- It is based on satellite DNA, especially VNTRs (Variable Number Tandem Repeats) - short sequences repeated in tandem, whose number varies among individuals and creates DNA polymorphism.
- Principle: the differences in VNTR repeat number produce DNA fragments of different lengths, which appear as a unique banding pattern.
- Steps: DNA isolation → PCR amplification → restriction digestion → gel electrophoresis → Southern blotting → probe hybridisation → autoradiography → comparison of band patterns.
- Applications: forensic identification, paternity/maternity testing, pedigree studies, medical research, conservation biology, and evolutionary/anthropological studies.
