Definitions [36]
Long answer question.
What is metabolism?
Metabolism is the sum of the chemical reactions that take place within each cell of a living organism and provide energy for vital processes and for synthesizing new organic material.
Long answer question.
What are biomolecules?
Biomolecules are essential substances produced by our body which are necessary for life.
Long answer question.
What are the nucleic acids?
Nucleic acids are macromolecules composed of many small units or monomers called nucleotides.
Carbohydrates may be defined as optically active polyhydroxy aldehydes or ketones or compounds which produce such units on hydrolysis, such as cellulose, glycogen, starch, etc.
The sugars that reduce the Tollen's reagent and Fehling's solution are called reducing sugars.
Define carbohydrates.
Carbohydrates are optically active polyhydroxy aldehydes or polyhydroxy ketones or compounds that can be hydrolysed to polyhydroxy aldehydes or polyhydroxy ketones.
Carbohydrates that are amorphous solids, tasteless and insoluble in water are catled non-sugars.
Carbohydrates that are crystalline solids, sweet in taste and soluble in water are called sugars.
An aldose monosaccharide that has six carbon atoms (e.g., Glucose) is called an aldohexose.
A ketose with six carbon atoms is called a ketohexose.
Monosaccharides that contains one aldehydic group is called aldose.
A monosaccharide that contains one ketonic carbonyl group is called a ketose.
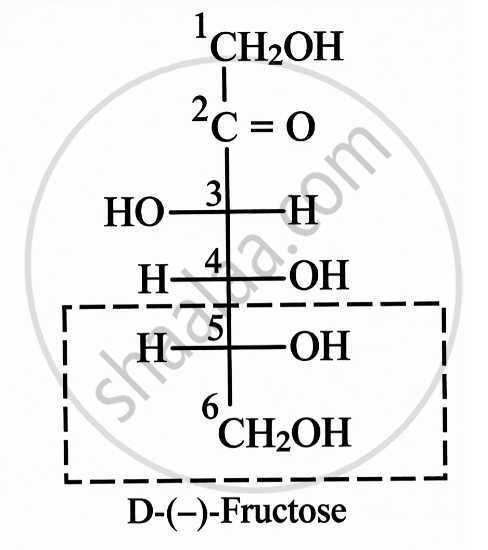
Fructose is another commonly known monosaccharide having the same molecular formula as glucose. It is levorotatory and a ketohexose. It is present abundantly in fruits, and hence it is also called fruit sugar.
Define α-amino acids.
α-Amino acids are carboxylic acids having an amino (–NH2) group bonded to the α-carbon, that is, the carbon next to the carboxyl (–COOH) group.
Chemically, proteins are polyamides, which are high molecular weight polymers of the monomer units called \[\alpha\]-amino acids.
Bifunctional organic compounds containing a carboxylic and an amino group either at the same carbon atom or at nearby carbon atoms are called amino acids.
Define peptide bond.
The bond that connects α-amino acids to each other is called a peptide bond.
Define enzymes.
Enzymes are biological catalysts that speed up chemical reactions in living cells without being consumed in the process.
Define the term Protein.
Chemically proteins are polyamides which are high molecular weight polymers of the monomer units, i.e., α-amino acids. OR It can also be defined as proteins are the biopolymers of a large number of α-amino acids and they are naturally occurring polymeric nitrogenous organic compounds containing 16% nitrogen and peptide linkages (-CO-NH-)
Proteins are complex polyamides formed from amino acids. They are essential for the proper growth and maintenance of the body. They have many peptide (-CO–NH )bonds.
Amino acids which contain more number of carboxyl groups than amino groups are called acidic amino acids.
Amino acids which contain equal number of amino groups and carboxyl groups are called neutral amino acids.
Amino acids which contain more number of amino groups than carboxyl groups are called basic amino acids.
Amino acids which are synthesised by the body itself are called non-essential amino acids.
Define the following term as related to proteins:
Primary structure
Proteins may have one or more polypeptide chains. Each polypeptide in a protein has amino acids linked with each other in a specific sequence and it is this sequence of amino acids that is said to be the primary structure of that protein. Any change in this primary structure, i.e., the sequence of amino acids, creates a different protein.
Define the following as related to proteins:
Peptide linkage
Chemically, peptide linkage is an amide formed between the –COOH group and –NH2 group. The reaction between two molecules of similar or different amino acids proceeds through the combination of the amino group of one molecule with the carboxyl group of the other. This results in the elimination of a water molecule and the formation of a peptide bond –CO–NH–. The product of the reaction is called a dipeptide because it is made up of two amino acids.
For example, when the carboxyl group of glycine combines with the amino group of alanine, we get a dipeptide, glycylalanine.
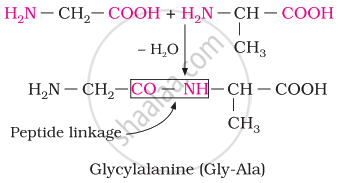
Define the following term as related to proteins:
Denaturation
Denaturation is the process in which the secondary and tertiary structure of a protein is disrupted due to heat, a change in pH, or chemicals, while the primary structure remains unchanged. In denaturation, peptide bonds are not broken; only the weak bonds (like hydrogen bonds) are disturbed.
When a protein, in its native form, is exposed to changes, such as temperature or pH, the hydrogen bonds are disrupted. Due to this, globules unfold, the helix uncoils, and the protein loses its biological activity. It is called denaturation of proteins, e.g., coagulation of egg white on boiling, curdling of milk, etc.
A colloidal solution of protein which works as a biological catalyst is known as an enzyme.
DNA is a double-stranded nucleic acid that stores and transmits hereditary information and can replicate itself.
A nucleotide is the basic structural unit of nucleic acids, composed of a nitrogenous base, a pentose sugar, and a phosphate group.
A nitrogenous base is an organic molecule (purine or pyrimidine) that carries genetic information in nucleic acids.
RNA is a single-stranded nucleic acid that helps in protein synthesis and information transfer.
A nucleoside consists of a nitrogenous base linked to a pentose sugar without a phosphate group.
Define the following term.
nucleoside
The unit formed by joining the anomeric carbon of the furanose (sugar) with a nitrogen of a base is called nucleoside.
Nucleic acids are large biological macromolecules that store and transmit genetic information in living organisms.
Key Points
- Carbohydrates are organic biomolecules made of C, H and O, usually fitting the general formula Cx(H₂O)y and existing as aldoses or ketoses.
- They are classified into monosaccharides, disaccharides and polysaccharides; monosaccharides cannot be hydrolysed further, disaccharides are formed by two monosaccharides via glycosidic bonds, and polysaccharides are long polymers.
- Some sugars like digitoxose (C₆H₁₂O₄) and rhamnose (C₆H₁₂O₅) do not obey the typical Cx(H₂O)y formula.
- All monosaccharides are reducing sugars because they possess a free aldehyde or ketone group.
- Cellulose is a linear polymer of β‑D‑glucose, unlike starch and glycogen, which are polymers of α‑glucose and show branching.
- Biologically, carbohydrates supply energy for metabolism; glucose is the main substrate for ATP synthesis, and lactose provides energy to infants.
- Polysaccharides such as starch and glycogen act as storage products and also contribute to structural components of cell membranes and cell walls.
- Glucose is a monosaccharide, an aldohexose, and a reducing sugar, commonly found in fruits and also known as dextrose.
- It can be prepared by hydrolysis of sucrose (using dilute acid) or hydrolysis of starch under heat and pressure.
- Glucose confirms a straight-chain structure of six carbon atoms when reduced to n-hexane.
- Presence of functional groups is shown by reactions: –CHO (aldehyde), five –OH groups, and formation of derivatives like oxime and cyanohydrin.
- Oxidation reactions indicate the formation of gluconic acid (mild oxidation) and saccharic acid (strong oxidation), confirming functional groups in glucose.
| Product | Inference |
|---|---|
| n-Hexane (hot HI) | 6 C in a straight chain |
| Glucoxime (NH₂OH) / Cyanohydrin (HCN) | Carbonyl group present |
| Gluconic acid (Br₂ water) | —CHO group present |
| Glucose pentaacetate (acetic anhydride) | Five —OH groups present |
| Saccharic acid (dil. HNO₃) | One primary —OH group present |
- Glucose is an aldohexose with molecular formula \[C_{6}H_{12}O_{6},\mathrm{M.P.146^{\circ}C.}\]
- 'D' in D-(+)-Glucose = configuration; (+) = dextrorotatory nature; 'D'/'L' have no relation to optical activity.
- Glucose has five —OH groups (confirmed by glucose pentaacetate) and one aldehydic carbonyl group (confirmed by oxime & cyanohydrin formation).
- Glucose is soluble in water, sparingly soluble in alcohol, and insoluble in ether.
- The additional chiral centre in glucose ring structures is formed due to ring closure.
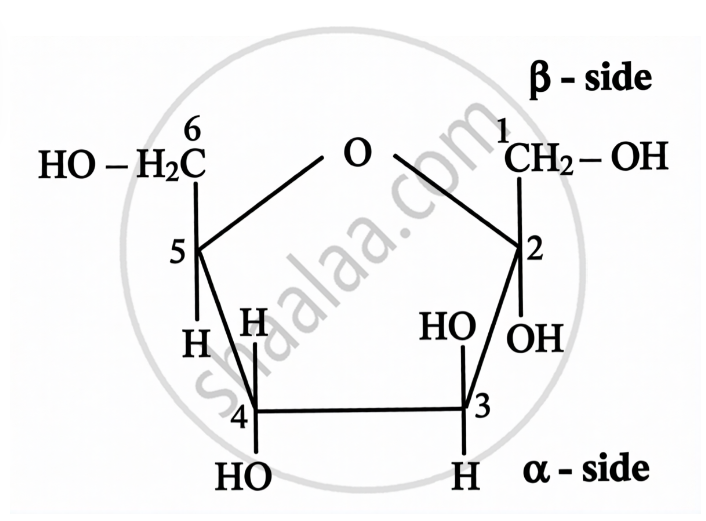
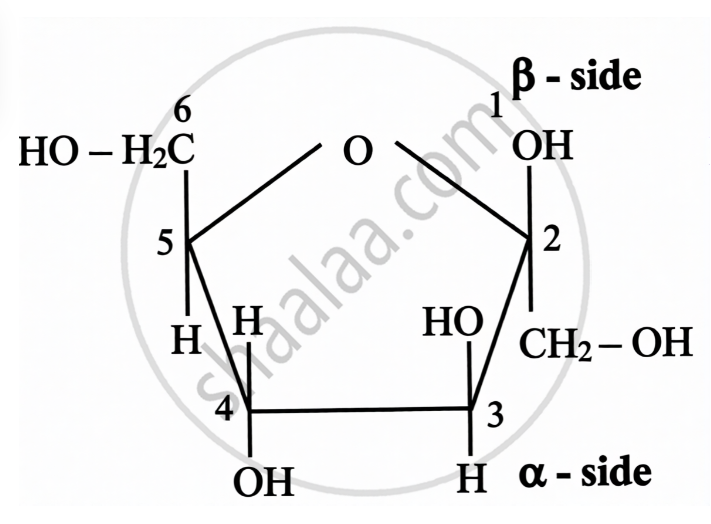
Structure of Fructose:
| Open Chain Structure | Ring Structure | |
 |
\[\alpha\]-D-(-)-Fructofuranose | \[\beta\]-D-(-)-Fructofuranose |
 |
 |
|
Preparation of Fructose:
-
From hydrolysis of cane sugar (sucrose):
\[ \underset{\text{Sucrose}}{\mathrm{C}_{12}\mathrm{H}_{22}\mathrm{O}_{11}} + \mathrm{H}_2\mathrm{O} \xrightarrow{\text{Dil } \mathrm{H}_2\mathrm{SO}_4} \underset{\text{Glucose}}{\mathrm{C}_6\mathrm{H}_{12}\mathrm{O}_6} + \underset{\text{Fructose}}{\mathrm{C}_6\mathrm{H}_{12}\mathrm{O}_6} \] -
From inulin:
\[ (\mathrm{C}_6\mathrm{H}_{10}\mathrm{O}_5)_n + n\mathrm{H}_2\mathrm{O} \xrightarrow{\text{Dil } \mathrm{H}_2\mathrm{SO}_4} \underset{\text{Fructose}}{n\mathrm{C}_6\mathrm{H}_{12}\mathrm{O}_6} \]
- Sucrose consists of one unit each of α-D-glucopyranose and β-D-fructofuranose.
- It contains an α, β-1,2-glycosidic linkage.
- Maltose is composed of two α-D-glucopyranose units joined by an α-1,4-glycosidic bond.
- Lactose consists of β-D-galactopyranose and β-D-glucopyranose units.
- It has a β-1,4-glycosidic linkage.
- Starch — A polymer of α-D-glucopyranose. It has two components: amylose (α-1,4-glycosidic linkage) and amylopectin (both α-1,4 and α-1,6-glycosidic linkages).
- Cellulose — A polymer of β-glucopyranose units linked by β-1,4-glycosidic bonds.
- Glycogen — A polymer of glucose units.
- Linkage Comparison —
Polysaccharide Monomer Linkage Amylose (Starch) α-D-glucopyranose α-1,4 Amylopectin (Starch) α-D-glucopyranose α-1,4 and α-1,6 Cellulose β-glucopyranose β-1,4 Glycogen Glucose — - Key Distinction — Starch and Cellulose are both glucose polymers but differ in linkage type: Starch has α-glycosidic bonds (digestible by humans), while Cellulose has β-glycosidic bonds (not digestible by humans).
- Proteins are polymers of amino acids (polypeptides) in which amino acids are linked by peptide bonds.
- There are 20 types of amino acids, so proteins are heteropolymers (not homopolymers).
- Amino acids are of two types: essential (must be obtained from diet) and non-essential (can be synthesised in the body).
- Proteins are high molecular weight biomolecules (polyamides) made of α-amino acids with a general structure R-CH(NH₂)-COOH.
- Proteins perform various functions such as enzymatic activity, transport, hormonal regulation, immunity, and sensory reception.
- Proteins are of two main types: fibrous proteins (insoluble, structural, e.g., keratin) and globular proteins (soluble, functional, e.g., enzymes, insulin).
- Collagen is the most abundant protein in animals, while RuBisCO is the most abundant enzyme in the biosphere.
| Sr. No. | Name | R Group | 3-Letter | 1-Letter |
|---|---|---|---|---|
| 1 | Glycine | H– | Gly | G |
| 2 | Alanine | CH₃– | Ala | A |
| 3 | Valine* | Me₂CH– | Val | V |
| 4 | Leucine* | Me₂CH–CH₂– | Leu | L |
| 5 | Isoleucine* | CH₃–CH₂–CH(Me)– | Ile | I |
| 6 | Asparagine | H₂N–CO–CH₂– | Asn | N |
| 7 | Glutamine | H₂N–CO–CH₂–CH₂– | Gln | Q |
| 8 | Serine | HO–CH₂– | Ser | S |
| 9 | Threonine* | CH₃–CHOH– | Thr | T |
| 10 | Cysteine | HS–CH₂– | Cys | C |
| 11 | Methionine* | Me–S–CH₂–CH₂– | Met | M |
| 12 | Phenylalanine* | Ph–CH₂– | Phe | F |
| 13 | Tyrosine | p–HO–C₆H₄–CH₂– | Tyr | Y |
| 14 | Tryptophan* | Indole–CH₂– | Trp | W |
| 15 | Proline | Entire ring structure | Pro | P |
| 16 | Aspartic acid (Acidic) | HOOC–CH₂– | Asp | D |
| 17 | Glutamic acid (Acidic) | HOOC–CH₂–CH₂– | Glu | E |
| 18 | Lysine* (Basic) | H₂N–(CH₂)₄– | Lys | K |
| 19 | Arginine* (Basic) | HN=C(NH₂)–NH–(CH₂)₃– | Arg | R |
| 20 | Histidine* (Basic) | Imidazole–CH₂– | His | H |
- Proteins are made up of α-amino acids linked together in a chain.
- A peptide bond (–CO–NH–) is formed between the carboxyl group of one amino acid and the amino group of another with the removal of water (condensation).
- Two amino acids form a dipeptide, three form a tripeptide, and many form polypeptides.
- Proteins are long polypeptide chains containing more than 100 amino acid residues.
- The ends of a protein chain are different:
The N-terminal has a free amino group, and the C-terminal has a free carboxyl group. - A peptide bond is similar to a secondary amide linkage in organic chemistry.
| Level | Description | Stabilising Forces |
|---|---|---|
| Primary | Linear sequence of amino acids linked by peptide bonds | Peptide bonds |
| Secondary | α-helix (right-handed coil, –NH of one AA H-bonded to C=O of 4th residue) OR β-pleated sheet (when R group is small) | Hydrogen bonds |
| Tertiary | Further folding of secondary structure; 3D shape | Hydrophobic interactions, H-bonds, disulphide bonds, van der Waals, ionic interactions |
| Quaternary | Two or more polypeptide chains arranged spatially | All forces present in tertiary structure |
- Enzymes are biological catalysts, mostly proteins, that increase the rate of biochemical reactions without being consumed.
- Some enzymes are ribozymes, which are RNA molecules that act like enzymes.
- Enzymes have primary, secondary, and tertiary structures, and their 3D structure determines their specificity and function.
- Each enzyme has a specific active site where the substrate binds to form an enzyme–substrate complex.
- Enzymes are highly specific and lower the activation energy of reactions.
- Enzyme activity is affected by temperature and pH; most enzymes are denatured at high temperatures, while thermophilic enzymes remain stable at 80–90°C.
- Examples of enzymes include amylase (starch → glucose), pepsin (proteins → amino acids), lactase (lactose → glucose + galactose), and maltase (maltose → glucose).
Mechanism of Enzyme Action (Lock and Key model):
- Enzyme (E) binds to substrate (S) → ES complex (E + S → ES)
- Product formation: ES → EP
- Product released: EP → E + P (enzyme regenerated)
- Enzymes work best at 298 K to 313 K (25°C to 40°C) — optimum temperature
- Activity decreases with temperature increase or decrease beyond optimum range; stops at ~273 K
- Nucleic acids are biomacromolecules present in the acid-insoluble fraction and are responsible for the storage and transmission of genetic information (DNA and RNA).
- They are polynucleotides, formed by repeated units called nucleotides.
- Each nucleotide consists of three components: a nitrogenous base, a pentose sugar, and a phosphate group.
- Nitrogenous bases are of two types: purines (adenine, guanine) and pyrimidines (cytosine, thymine, uracil).
- The sugar present is either ribose (in RNA) or 2′-deoxyribose (in DNA).
- DNA is double-stranded and contains bases A, T, G, and C, while RNA is single-stranded and contains A, U, G, and C.
- DNA stores genetic information, while RNA plays a key role in protein synthesis and the expression of genetic information.
- Nitrogenous bases in nucleic acids are of two types: purines and pyrimidines.
- Purine bases have a double-ring structure and include Adenine (A) and Guanine (G).
- Pyrimidine bases have a single-ring structure and include Cytosine (C), Thymine (T), and Uracil (U).
- Thymine is present in DNA, while Uracil is present in RNA instead of thymine.
Concepts [17]
- Biomolecules in the Cell
- Biomolecules in the Cell > Carbohydrates
- Monosaccahrides
- Preparation of Glucose
- Structures of Glucose
- Fructose
- Disaccharides
- Polysaccharides
- Biomolecules in the Cell > Proteins
- Classification of Amino Acids
- Peptide
- Structure of Proteins
- Denaturation of Proteins
- Biomolecules in the Cell > Enzymes
- Mechanism of Enzymatic Action
- Biomolecules in the Cell > Nucleic Acids
- Structure of Nucleic Acids
